
Geminiが楽しみすぎる〜本当のマルチモーダルAIがついに登場!?

ChatGPTを超えるAIの登場!?
よくChatGPT超え!?なんて形容詞がついているサービスも見かけましたが、今回こそChatGPTを超えるのか。GoogleのGeminiが登場です。まだ英語だけですが。
今までいろんなテクノロジーで革新がありました。私は電話会社に勤めていたこともあって、2004年にSKYPEが出たときにはびっくりしました。すごい。海外の親戚から電話がかかってきても時間を気にせずに話すことができる。これは電話会社の未来は暗いなあ、と思ったものです。
それが理由で独立したわけではないですし、電話会社はまだまだ日本では元気のままなので、私の未来予測力も大したことないな、と思います。
とはいえ2020年コロナが来て以降、ZoomやTeamsなどのサービスが急速に普及し、我々の働き方を大きく変えました。残念ながらSkypeは買収などもあってブレイクしきれませんでしたが、Web会議サービスの先駆者として世界を良くすることに貢献したのだと思います。
ChatGPTもそうなるのかな、なんて思います。生成AIのテキスト分野では、強烈なインパクトを残しました。というかまだインパクトを与え続けています。
とはいえ、これからGoogleなりMicrosoftの提供サービスに巻き取られ、Skypeのようになっていくのかなあ。(SkypeはMicrosoftに買収された)
この分野でどこが勝ち残るのかわかりませんが、やはり既存サービスとの融合という点では、GAFAの方が有利な気もします。ChatGPTで分析するより、エクセルの中でAIがついてそのまま分析できた方が便利ですしね。
どうなっていくか楽しみです。
ということでGoogleのGemini
この動画のとおり動くのならすごいですね。テキスト、動画、イラスト・・・それも手書きや人形も巻き込んでAIで対応できる。
Googleの新AI「Gemini」、もはや人間では?凄さが分かる短編動画 (PC WATCH)
https://pc.watch.impress.co.jp/docs/news/1552697.html
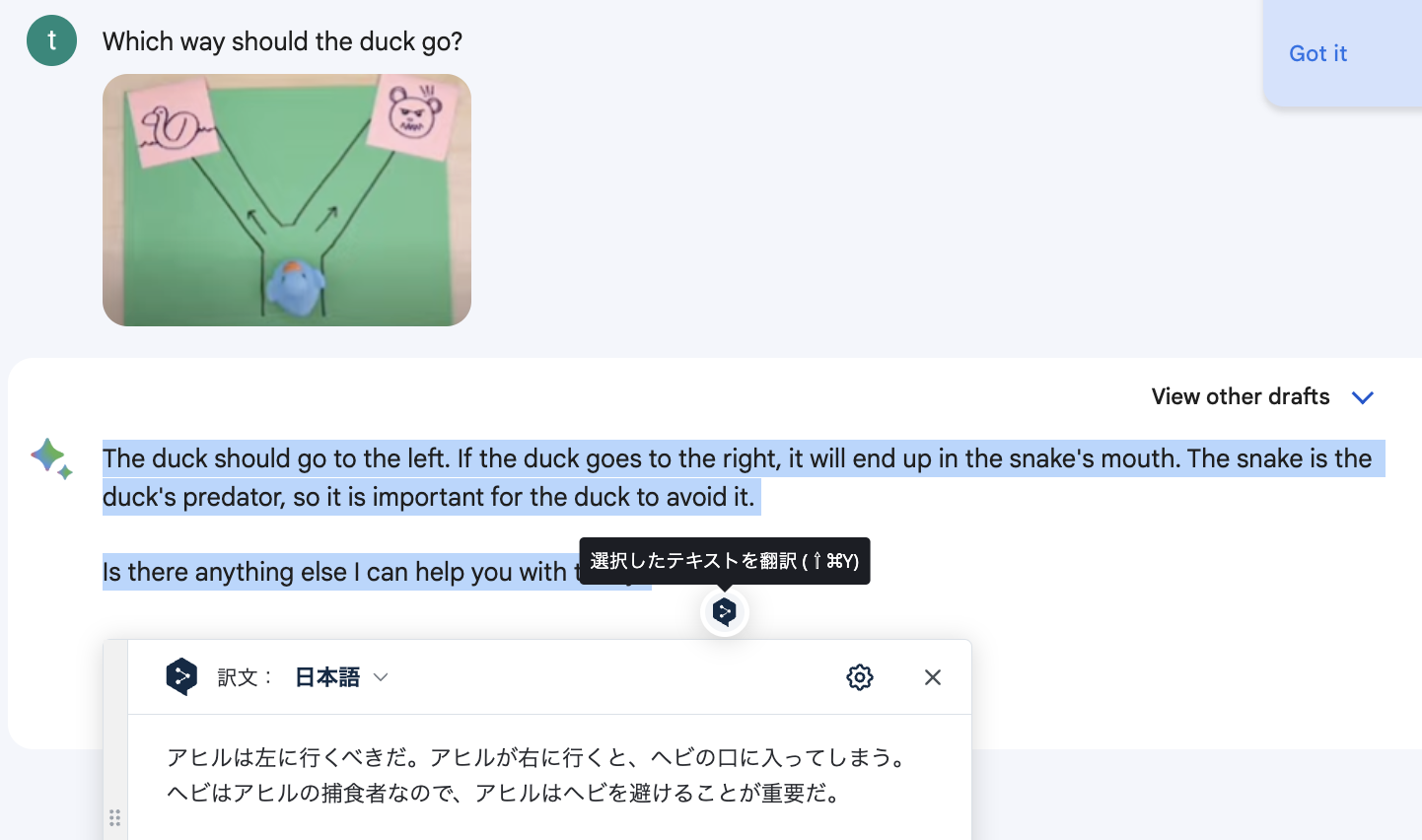
手書きのイラストとかアヒルの人形を並べて、どっちに行くべきかと聞くと、友達の左のアヒルにいこう!といってくれます。うーむ。すごそうですが、普通そうでもあります。やはりマルチモーダルということで画像だけでなくいろんな状態を一度に認識して処理してくれるのがすごいですね。

Geminiの特徴を教えてください とGoogleBardに聞いてみました。
Geminiの特徴は、以下のとおりです。
- マルチモーダル能力
Geminiは、テキスト、画像、音声、動画などの複数の情報を同時に処理できるマルチモーダル能力を備えています。これにより、従来のAIモデルでは困難だった、テキストと画像の相互関係の理解や、音声と映像の同期などのタスクを実行することができます。
- 高精度
Geminiは、テキスト生成、翻訳、質問応答などのタスクにおいて、従来のAIモデルを上回る精度を実現しています。
- 汎用性
Geminiは、さまざまなタスクに対応できる汎用性の高いモデルです。そのため、特定の分野に特化したモデルを開発する必要がなく、幅広い用途に活用することができます。
- 学習効率
Geminiは、少量のデータからでも高い精度を達成することができます。そのため、データの収集や準備にかかるコストを削減することができます。
具体的な例としては、以下のようなタスクに活用されています。
- テキスト生成:ニュース記事や小説などのテキストを生成
- 翻訳:言語間の翻訳
- 質問応答:ユーザーの質問に答える
- 画像認識:画像から物体や人物を認識する
- 音声認識:音声からテキストを起こす
Geminiは、今後さまざまな分野で活用される可能性を秘めた、画期的なAIモデルです。
高精度、汎用性、学習効率と言われても使う側にとってはあまり特徴に感じないので、やはりマルチモーダルということがウリなんでしょうかね。
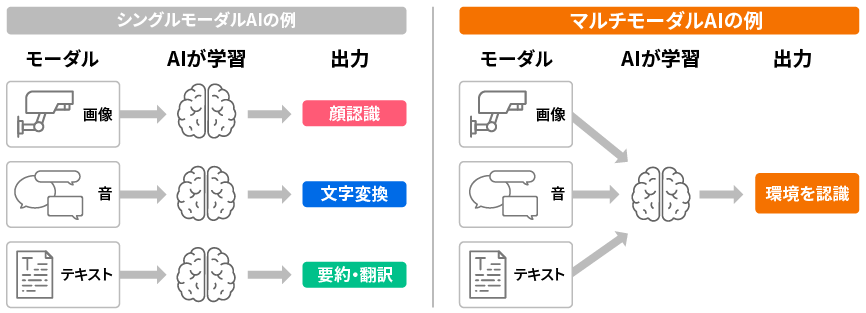
特徴1 マルチモーダル
マルチモーダルとは異なる種類の情報、すなわちテキストだったり、画像だったりマイクの音声だったり、動画であったりをすべてまとめて取り扱うことです。ChatGPTでももちろんすべての情報が取り扱えるのですが、ChatGPTはそれぞれ別々の情報を学習させて、最後に統合した感じなのに比べて、Geminiは最初からマルチモーダルで学習してきたので、この分野ではより性能が高い!としています。
もちろんまだ確認市ていないのでどれほど高いのかはわかりませんが、ベンチマークの結果などでは高い数値が出ています。
マルチモーダルAIとは、異なる種類の情報をまとめて扱うAIのことです。例えば、カメラで撮影した映像とマイクで録音した音という異なる種類の情報から1つのAIを学習させることで、映像の中に写っている人が何を話しているのかをより正確に推定できます。マルチモーダルAIの研究が発展すると、複合的な情報から判断が必要なアシスタントロボットが作られたり、もっと少ないコストでAIを作れるようになったりと、AIがさらに高度で身近な存在になるでしょう。
https://www.aist.go.jp/aist_j/magazine/20231129.html
出典 産総研マガジン
どうでもいいけどGemini.comじゃなかった
早速Geminiを試そうとと思って、Geminiって検索したら、 Gemini.comがでてきて、ああ仮想通貨ですかw Google的にはGeminiでドメインを取れてなくていいんでしょうかね。それはさておき。
Geminiを使ってみるには
GoogleBardを英語版にして使ってみました。新しいサービスは英語版から出ることが多いので、わたしはGoogleアカウントを最初から英語に設定したものを作っています。
とりあえずは、デモに出てきた画像をアップして アヒルはどっちに行くべきか?と聞いたら、 ちゃんと左へ!と言った。 (ただ右側は 熊ではなくヘビだと言っている・・画像の解像度が低かったですかね)
ChatGPTにも同じことを聞いてみる
まあでもこれくらいならChatGPTでも答えますね。すでに一枚の画像になっているからマルチモーダルというより、ただの画像認識ですもんね。

なにはともあれ、日本語対応がどれくらいでできてくるのか楽しみに待っています。
画像、動画、音声、テキストをすべて操る全能の猫のイラストを横長サイズでお願いします。
そんなとこで
